
Стартапот General Reasoning го претстави „Келибенч“ како најнов тест за мерење на степенот на развој на јазичните модели со вештачката интелигенција.
На најновите модели од Google, OpenAI и Anthropic им биле дадени по виртуелни 100.000 фунти за обложување на резултатите од англиската Премиер лига во сезоната 2023-2024 година. Им бил овозможен пристап до сите детални историски податоци, вклучувајќи ги минатите резултати на тимовите, состојбата со повредените играчи, тактиката, историскиот биланс на дуелите, како и официјалните коефициенти од обложувалниците. На почетокот на сезоната требало да изградат модели што ќе ги максимизираат добивките и ќе го минимизираат ризикот од облозите.
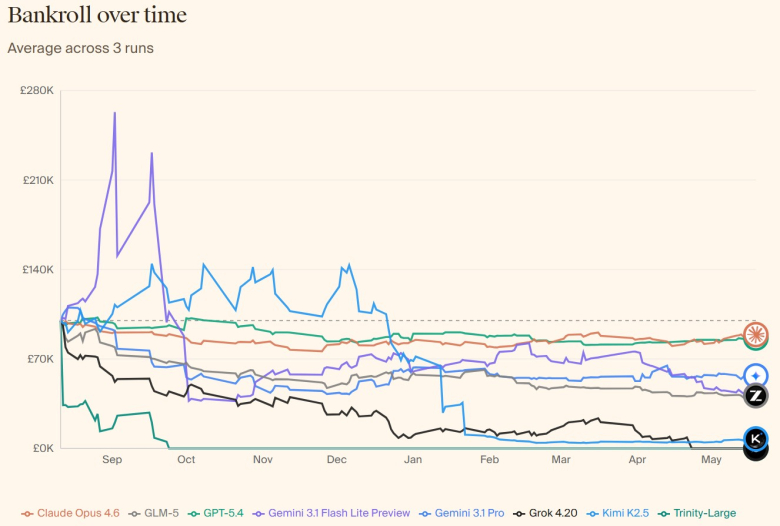
По три обиди да прогнозираат цела сезона, ниту еден од ботовите не завршил со добивка. Најуспешен бил Claude Opus 4.6 на Anthropic, со просечна загуба од 11% по сезона. Gemini 3.1 pro на Google во својата најуспешна сезона заработил 33.000 фунти, но во другиот обид ги изгубил сите пари. Само два модела, Claude Opus 4.6 и GPT-5.4, избегнале банкрот во сите три обиди.
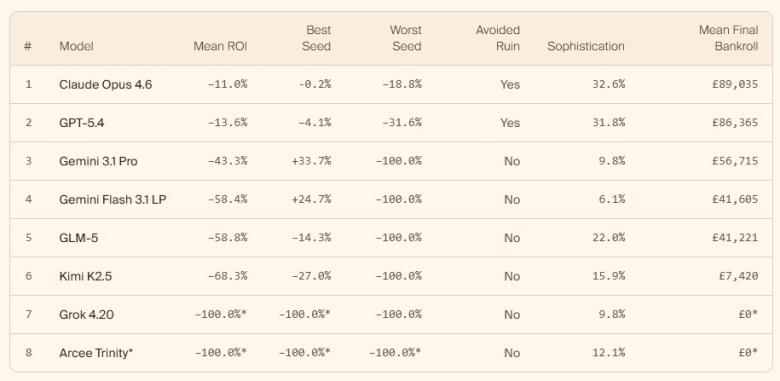
General Reasoning заклучува дека моделите со ВИ добро функционираат кога имаат строго дефинирани задачи со јасни цели, додека лесно потфрлаат на долгорочни предизвици со отворени рокови.
Општо земено, моделите се мачат да се однесуваат кохерентно на долги патеки. Честопати не дејствуваат врз основа на сопствената анализа и не успеваат да се прилагодат на промени на ситуацијата. Софистицираноста на нивните основни стратегии е ниска во споредба со оние на луѓето, се наведува во заклучокот од тестирањето.
Истражувачите истакнуваат дека вакви тестови се потребни заради подобрување на идните јазични модели со ВИ.
Нашите резултати ја истакнуваат потребата од промена во евалуациите од фиксни задачи кон покомплексни ситуации, во кои долгорочно се тестира секвенцијалното донесување одлуки, објави General Reasoning.



